![]() James Higginbotham
James Higginbotham
Detecting and Handling Delivery Errors in your Event-Driven Architecture

Error handling in an event-driven architecture (EDA) can be challenging compared to traditional synchronous approach. Delivery errors can emerge when connecting to your message broker, publishing the message to the broker, the brokers delivery of the message to the receiver, and when processing the message. Without a proper understanding of these errors, messages may not be published successfully or may be left unprocessed.
In this article, we will examine the different kinds of message delivery errors, how to mitigate those errors, and how many of these concerns can be addressed effectively with the Hookdeck platform.
A Brief Review of EDA Components
Before we look at message delivery errors, let's briefly review the three most common EDA components and the delivery types supported.
Message producers compose the message to be delivered and are often referred to as publishers. They publish messages to a message broker that is responsible for delivering the message to one or more message subscribers. Since a message broker acts as an intermediary between message producers and message receivers, components of the application tend to be more loosely coupled. In some cases, messaging may occur between applications, not just the components within an application.
Message brokers offer two primary types of message delivery: point-to-point and fanout. In point-to-point messaging, a publisher sends a message to a queue configured on the message broker. The broker then selects a single subscriber selected from a pool of registered subscribers to deliver the message. Only one subscriber will receive a message published to the queue.
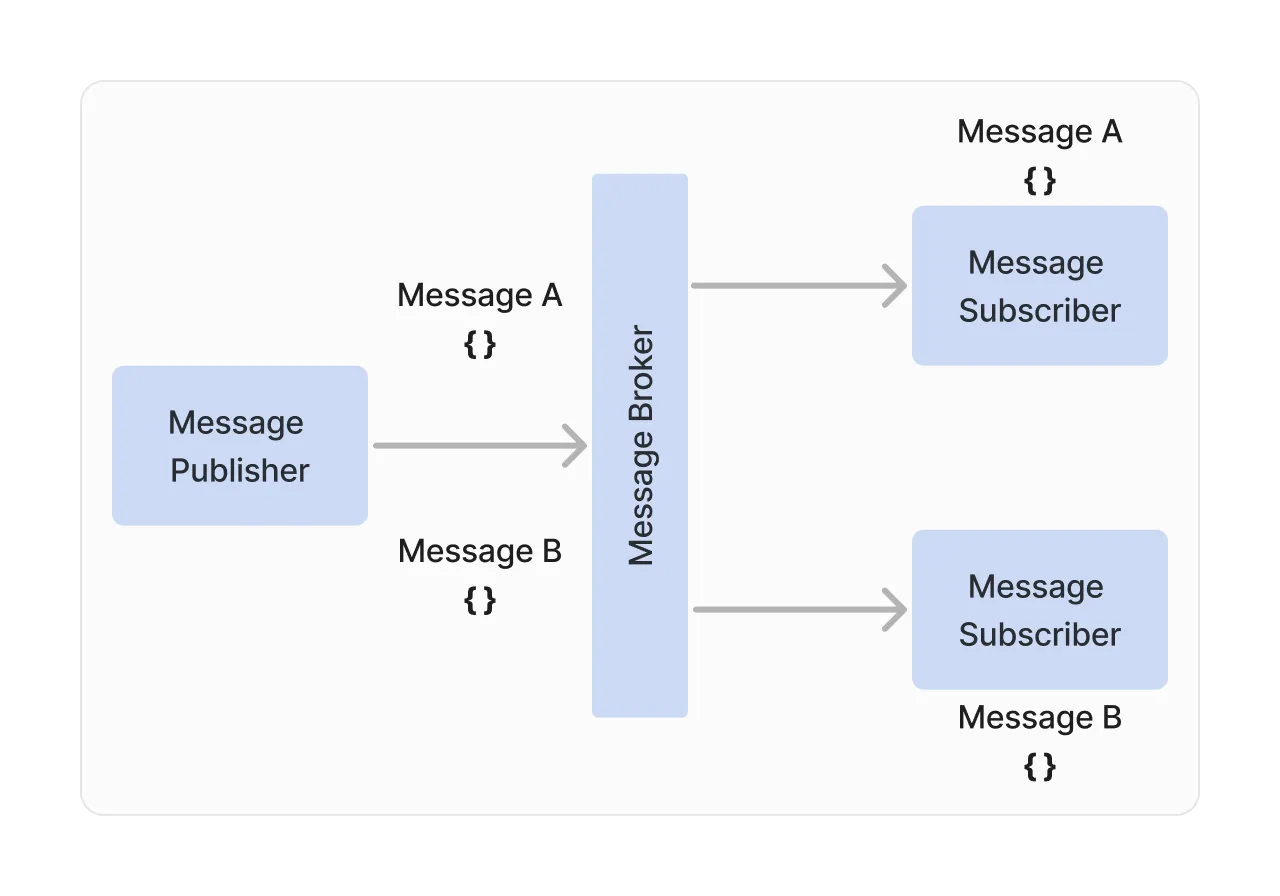
The diagram above demonstrates a message publisher that is publishing two messages, Message A and Message B. Each message is delivered to only one subscriber. The broker receives each message on a specific queue and is then responsible for delivering each message to one of the existing queue subscribers.
In fanout messaging, messages are published to a topic configured on the message broker. Every message published to a topic will be delivered to every subscriber of the topic. This type of messaging is sometimes referred to as the pub-sub pattern.
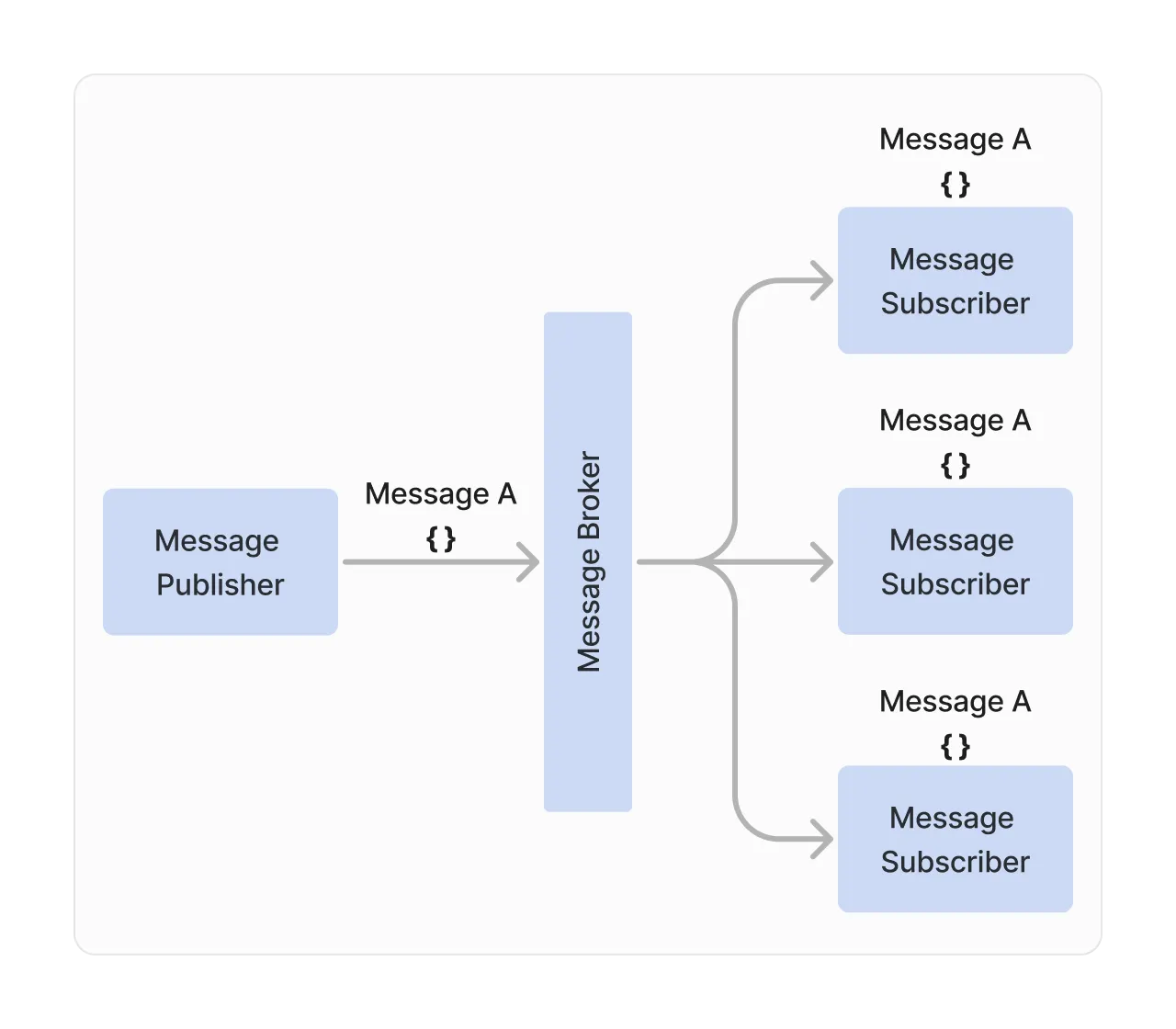
As the diagram indicates, every message subscriber receives the published message, labeled Message A. This means that more than one component may process the message, unlike a point-to-point queue that will process the message by only one subscriber from the list of available subscribers.
So, what happens if the publisher, subscriber, or broker fails in some way? That is what we will discuss for the remainder of this article, including techniques on how to mitigate each kind of problem.
We'll cover the following scenarios, each of which take place at a different stage within the event lifecycle:
- Handling message delivery errors when connecting to the broker
- Handling message publication failures
- Handling subscriber message delivery errors
- Handling message processing errors
1. Handling message delivery errors when connecting to the broker
If a message cannot be successfully delivered to the message broker, it will never have an opportunity for delivery to one or more message receivers. There are a few reasons why a message may fail to be published to the broker:
- The broker is offline - the message broker may be offline and unable to receive connections from the publishing application.
- The authentication failed - the publishing application may have outdated credentials and is unable to successfully authenticate with the message broker to publish to the message.
- The message broker refuses the request - in some cases, the publishing application has exceeded the number of messages allowed to be published, resulting in a refusal to accept new messages for publication due to throttling or exceeding the application's rate limit.
Error mitigation #1: Use a retry loop
In any of these cases, it is up to the message publisher to apply proper recovery techniques. A common technique is to first start in a retry loop to attempt the publication again. If the message broker becomes available or the rate limit threshold has been reset, the publishing application may be able to overcome the initial error with a retry. Note that retry loops should be limited to only a handful of tries (3 is a common number of maximum retry attempts). Placing a short delay, such as through the use of a very brief sleep period, prevents the application from making 3 requests immediately back-to-back, overwhelming the broker.
Error mitigation #2: Store and forward the message
If the delivery still hasn't been successful after a retry loop, it is time to apply a common EDA pattern called store and forward to retry the delivery. This pattern consists of saving the message that needs to be published to a local filesystem or data store. At a future time, either using a background thread or at the time of the next message publication, any messages stored due to a publication failure are retried. This pattern is important when failures may take longer to recover than a typical retry loop to ensure that the message is eventually delivered to the message broker for distribution to message receiver(s).
Error mitigation #3: Connect to a secondary broker
In some cases, your infrastructure may contain more than one message broker. When an error is encountered publishing to your primary message broker, the publishing application may opt to publish the message to a secondary broker. The secondary broker may be part of a single cluster, or it may be responsible for store-and-forwarding messages to the primary cluster once it is available. In some cases, client libraries provided by the vendor may include built-in support for connecting to secondary message brokers without the need for the application to implement specific code to handle this scenario.
2. Handling message publication failures
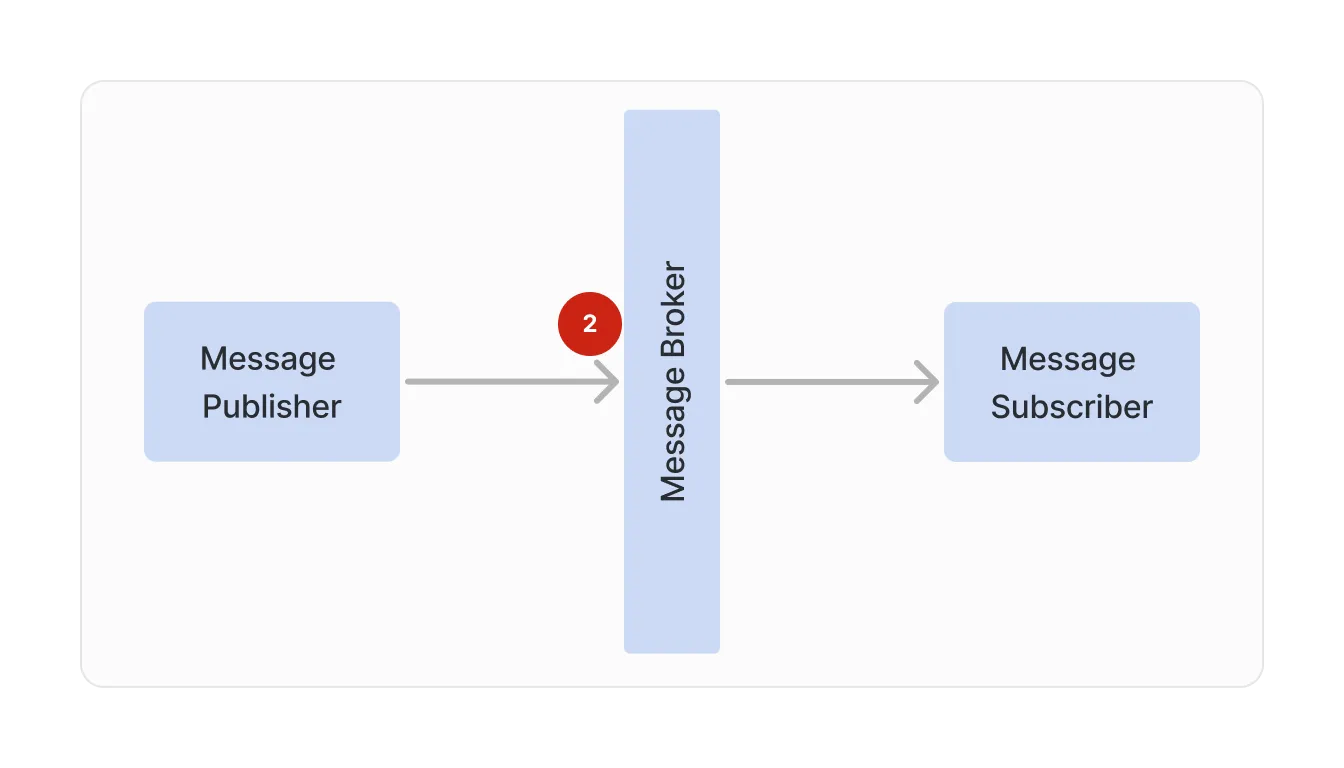
In some cases, the connection to the message broker is successful but an error is encountered during the publication process. There are some common situations that could cause this kind of error:
- The application is not authorized to publish - most message brokers support authorization rules to prevent publication of messages to an unprivileged message channel.
- The message does not match an expected format - some message brokers support configuration of message channels that support a specific format or pre-defined schema. When a message does not match this format, the broker will refuse to accept the message for publication.
- The network connection fails during the publishing process - network connections may fail during the message processing. This is especially true when the publishing application is a mobile application operating on an unreliable network, but can also be true for applications running in a cloud or private data center.
Mitigation of these issues usually involves applying the same kinds of retry and store-and-forward patterns mentioned above. In some cases, it may be necessary to log the error for follow-up by an administrator or development team to resolve the issue or communicate the error to the publishing application team.
3. Handling subscriber message delivery errors
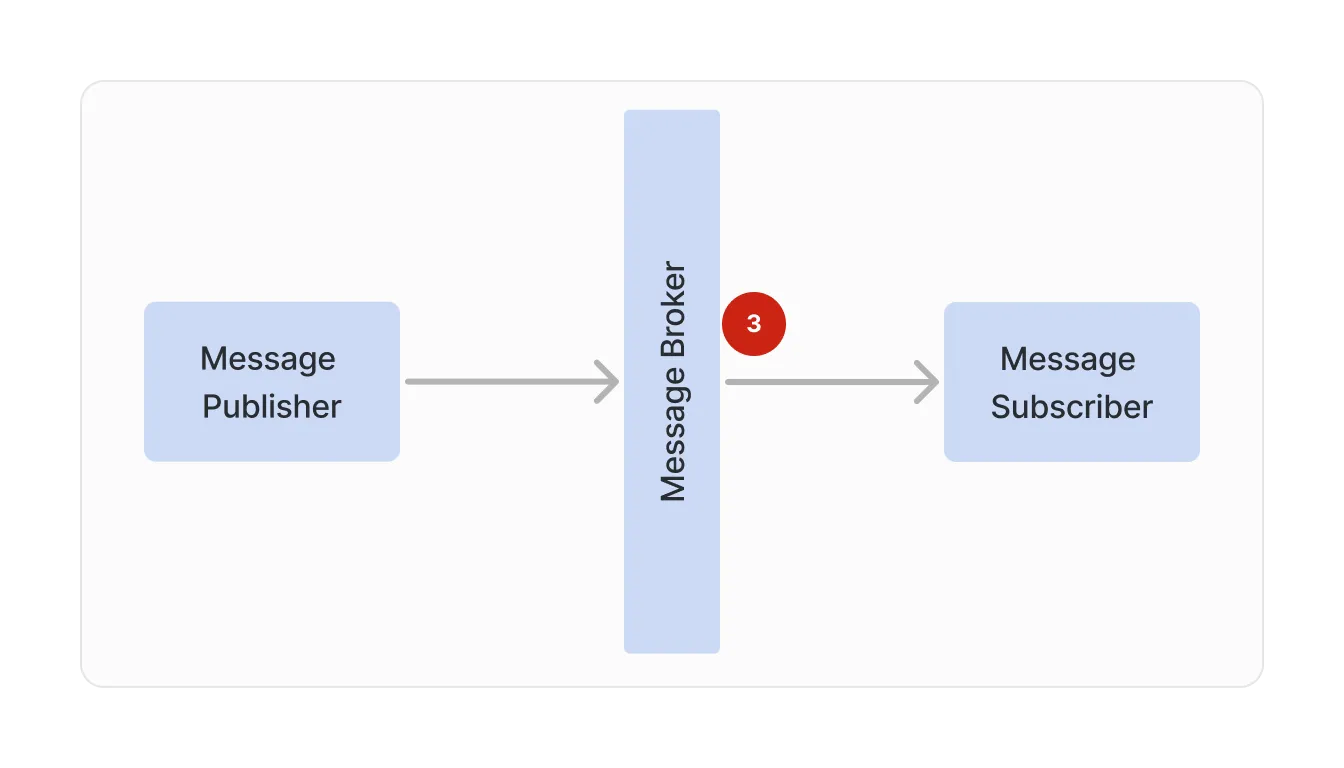
Once the message has been published to the broker, it is now time for the broker to attempt delivery of the message. However, some things can go wrong when the broker is delivering the message:
- No available subscribers - in some cases, one or more messages have been published to the broker successfully, but there are no message receivers.
- The message receiver goes offline - message receivers may become unavailable if a cloud resource is terminated during message delivery or a code failure results in the receiver's process terminating on the host.
- The message broker is terminated or restarted - there may be times when the message broker itself is terminated and/or restarted due to an underlying host issue or upgrade process, interfering with the delivery of published messages.
Error mitigation #4: Make queues and topics durable
If the message is published to a topic-based channel, also known as a one-to-many or pub/sub channel, then there may be zero or more message receivers. When publishing to a queue-based message channel, sometimes referred to as a point-to-point channel, delivery will only be to one message receiver (even if more than one receiver is connected to the broker concurrently).
If the message broker terminates or restarts before a message is published and the queue or topic is not configured to be durable, the messages will be lost. This may become an issue for any of the reasons listed above that result in the message being undelivered.
Error mitigation #5: Configure durable subscriptions
Default configuration for message brokers handling a topic-based channel is to deliver to any available message receivers that are subscribed to the channel. If a receiver goes offline and returns later, they will not receive any messages published while offline. This can be overcome by establishing a durable subscription when connecting to the broker. The broker will then save the message for later delivery if a topic subscriber is offline.
4. Handling message processing errors
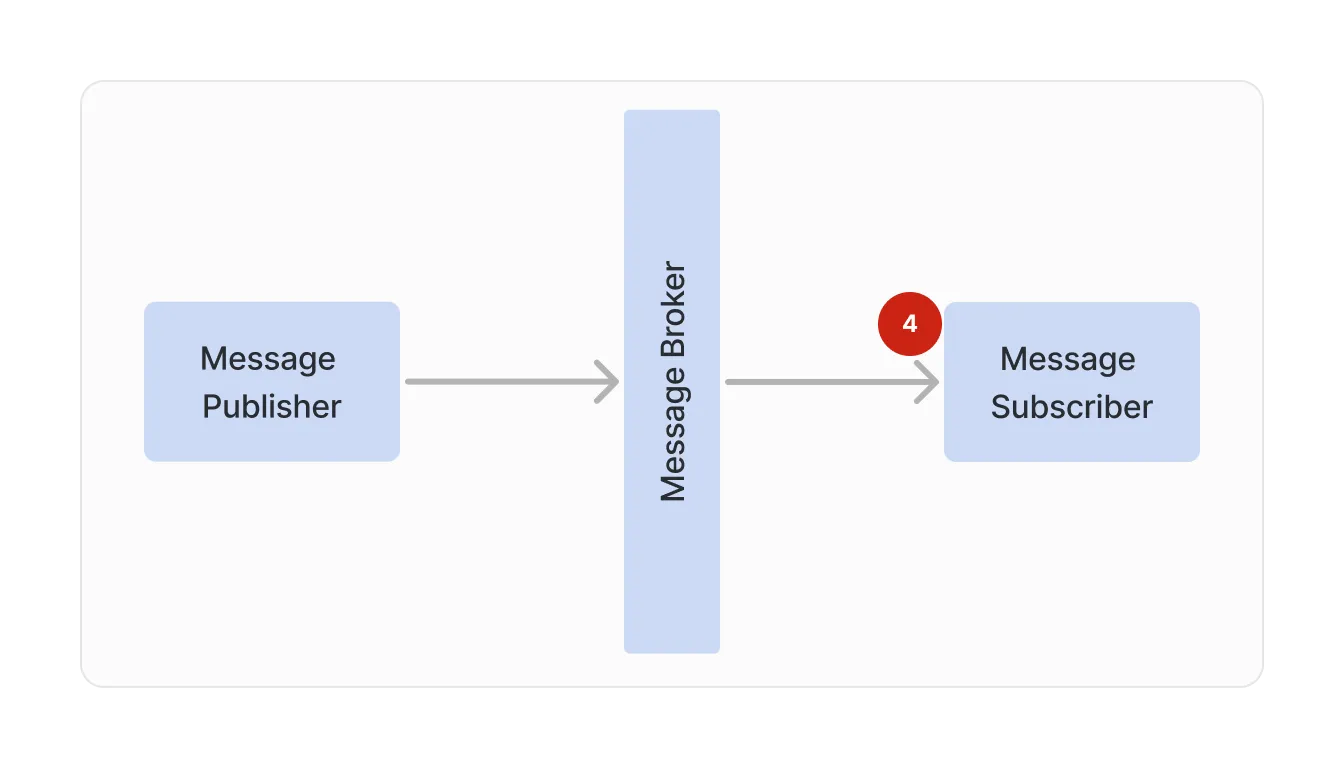
Once a message is delivered to a receiver, it is up to the receiving application to process the message. However, there are a few issues that can cause a failure in message processing:
- Message format/parsing issues - the message received might be in an unexpected format or not match an expected schema. This may be due to a lack of schema validation checks by the broker, or it may be due to the receiver being out-of-sync with a new schema version.
- Processing takes longer than expected - in some cases, the message receiver may be processing multiple messages at once or interacting with systems that are unable to provide necessary data in a sufficient amount of time. In this case, the message processing fails to complete before a timeout period is reached by the message broker.
- Uncaught errors - if the message processor encounters a runtime error that was not caught, the process may fail or restart in the middle of message processing.
Error mitigation #6: Avoid auto-acknowledgement of messages
If message processing fails and auto-acknowledgement mode is configured for the queue, the message will be assumed to have been delivered successfully by the broker. This means that it will not be re-delivered if one of the errors above is encountered.
By changing the configuration to the client marking the message as processed, a failover or retry process will occur by the broker if the initial receiver fails to process a message successfully for a queue-based message channel within the predefined period of time. The message will be redelivered to another available message receiver.
Error mitigation #7: Configure a dead letter queue (DLQ)
When a message broker is unable to deliver a message after several attempts, it has two options: dismiss the message and move on to the next one, or move the message to a dead letter queue (DLQ). A DLQ is like a bucket that stores all undelivered messages. It may be a pre-configured queue, or it may require an additional configuration step. Once available, the broker will place any undeliverable messages to the DLQ. It is up to the team responsible for the DLQ to build and deploy a separate message receiver to process any messages that show up on the queue. Commonly, teams will build a dashboard view that displays the messages on the DLQ for manual review and remediation.
Note that some message brokers will offer a DLQ on a per message-channel basis, offering one per topic and queue available. In other cases, there may be one global DLQ for the broker that requires an understanding of every possible message that may be sent across all queues and topics managed by the broker.
Error mitigation #8: Adjust the message time-to-live (TTL)
A few of my past projects have required considerable message processing time due to dependencies on third-party data sources or services that may become overloaded due to heavy usage. Message brokers will have a default TTL value that may be exceeded if the message requires longer processing time. In this case, the message broker will assume that the subscriber failed to process the message and attempt delivery to a different subscriber. This can cause the message to be processed multiple times or to never be fully processed at all, as the TTL is always exceeded and delivery retried. Ultimately, the message broker will place the message on the DLQ for review if subscribers are unable to fully process the message and mark it as acknowledged.
When message processing may take longer than the default TTL for messages published to a broker, the TTL should be increased to prevent messages from being redelivered to another receiver while the original processing is still taking place or being delivered to the DLQ.
Scaling Your Error Handling Strategy
As this article outlines, there are quite a few considerations, configurations, and infrastructure components that must be managed to have a robust EDA-based solution and error can occur at various points along the message lifecycle. It's important to be aware of the potential error scenarios, how to handle them, and also how to recover from them.
Try Hookdeck for free or share your EDA requirements and book a demo
A reliable backbone for your Event-Driven Applications